
最近基于Stable Diffusion XL(SDXL)开发了一个Wordpress插件。顺便总结一下。
一、Stable Diffusion是什么?
Stable Diffusion是一个开源的图像生成大模型。
目前主要使用的版本就是Stable Diffusion XL,也就是SDXL。
官网:Stability AI
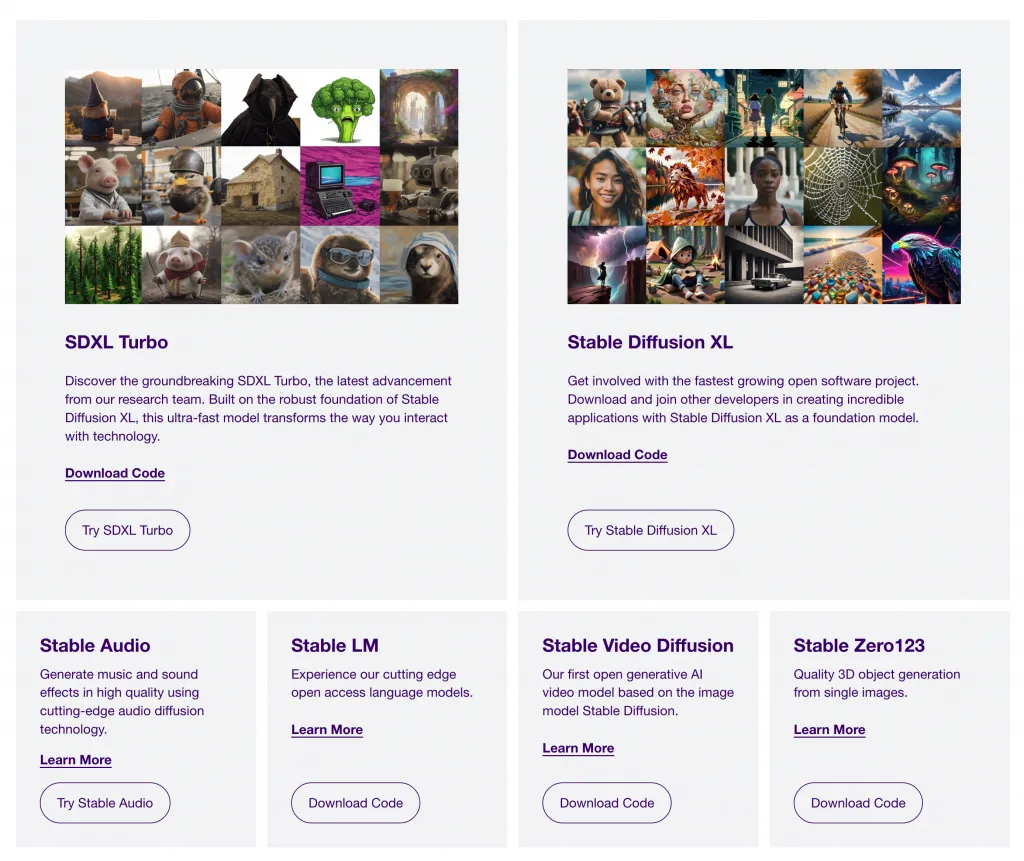
stability.ai的大模型家族
二、Stable Diffusion是免费的吗?
Stable Diffusion以及 Stability AI其它的大模型(包括视频、语音、3D)等都是免费开源的。你可以从官网直接现在代码部署到你自己的电脑或服务器上。
但,大多时候,我们不会自己部署,因为成本比较高,难度也比较大。所以,更多的时候,开发一个基于Stable Diffusion的产品,我们需要调用官网或第三方的Stable Diffusion的API,但,这样,就需要支付接口使用费。
三、如何部署Stable Diffusion?(由Google Gemini生成)
部署Stable Diffusion模型
方式 1:使用预构建的Docker映像
-
拉取 Docker 映像:
docker pull stabilityai/stable-diffusion:latest
-
创建并启动容器:
docker run -it --gpus all stabilityai/stable-diffusion:latest
方式 2:手动部署
-
安装依赖项:
-
Python 3.10.x
-
PyTorch 1.13.0+
-
torchvision 0.14.0+
-
ax-platform 0.3.11
-
transformers 4.28.0+
-
accelerate 0.9.1+
-
kornia 0.6.2+
-
einops 0.4.1+
-
huggingface_hub 0.10.0+
-
-
克隆 Stable Diffusion 存储库:
git clone https://github.com/huggingface/diffusers
-
安装 Stable Diffusion 库:
-
cd diffusers -
pip install .
-
-
下载模型权重:
wget https://huggingface.co/CompVis/stable-diffusion-v1-5/resolve/main/sd-v1-5.ckpt
-
部署模型:
-
创建一个 Python 脚本,加载模型并为其设置输入。
-
使用
diffusers.pipelines.stable_diffusion.StableDiffusionPipeline类运行图像生成。
-
使用说明
通过上述步骤部署 Stable Diffusion 模型后,可以使用以下命令生成图像:
from diffusers import StableDiffusionPipeline
# 加载模型
pipeline = StableDiffusionPipeline.from_pretrained("YOUR_MODEL_PATH")
# 运行图像生成
image = pipeline("YOUR_PROMPT")提示
-
使用
--gpus all标志来利用所有可用的 GPU。 -
调整
batch_size和num_outputs参数以控制生成图像的数量和质量。 -
使用
save_image()方法将图像保存到本地磁盘。
四、如何使用Stable Diffusion API?
在这个网站可以轻松部署自己的开源大模型。也可以使用别人部署的大模型的API。
1、使用你的GitHub账号登录这个网站
2、进入dashboard
3、选择一个图像生成模型
https://replicate.com/collections/text-to-image
这里列出了所有推荐的图像生成模型。
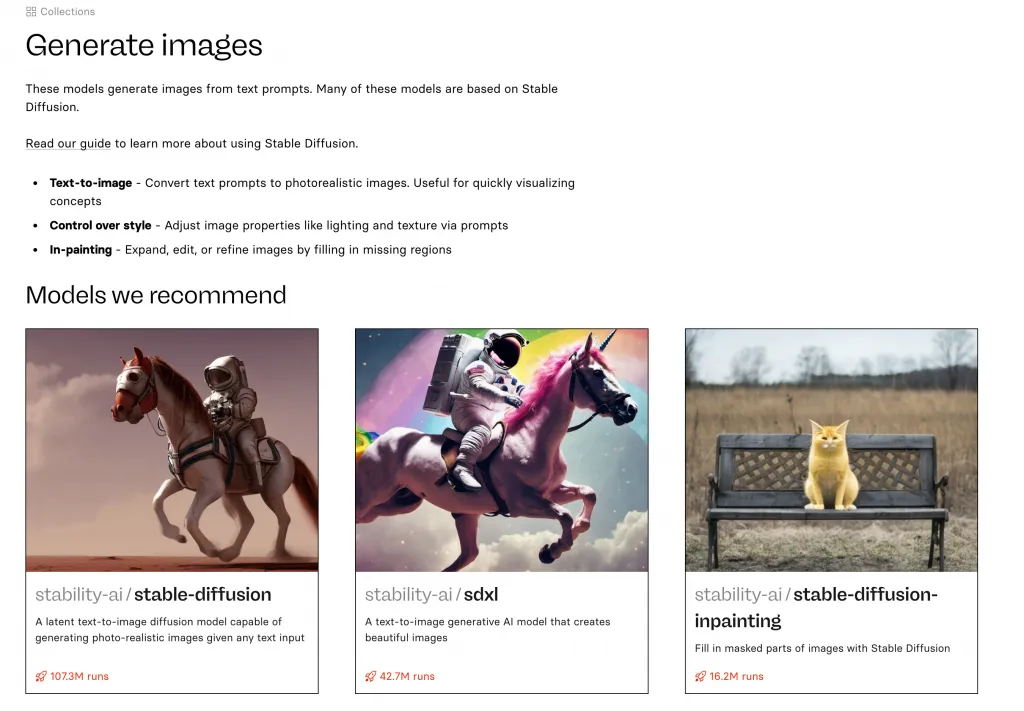
4、使用模型的API
这里有多个stable diffusion和sdxl的模型,选择一个即可。我们可以选第一个。点击进去,找到它的http API页面:
stability-ai/stable-diffusion – Run with an API on Replicate
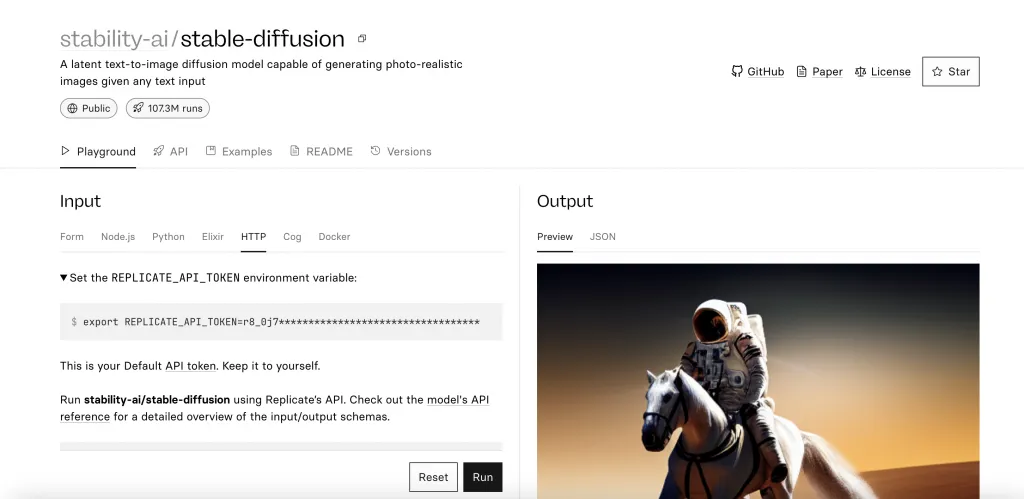
这里就是这个模型的API和调用代码示例。
也可以使用封装好的js、python等sdk。
五、总结
Stable Diffusion,免费、开源、通用,SDXL也是目前应用最多的图像生成大模型,可以帮你实现各种图片生成类的AIGC产品。