
现在,有很多朋友每天主用的Agent都已经是Codex了。我这几个月,也是以codex为主。
Codex有5小时用量限制和每周用量限制,而我平时的用量也比较大,经常一两个小时,就把5小时用量用完了。所以,不得不尝试节省token,让有限的token产出更多和更好的结果。
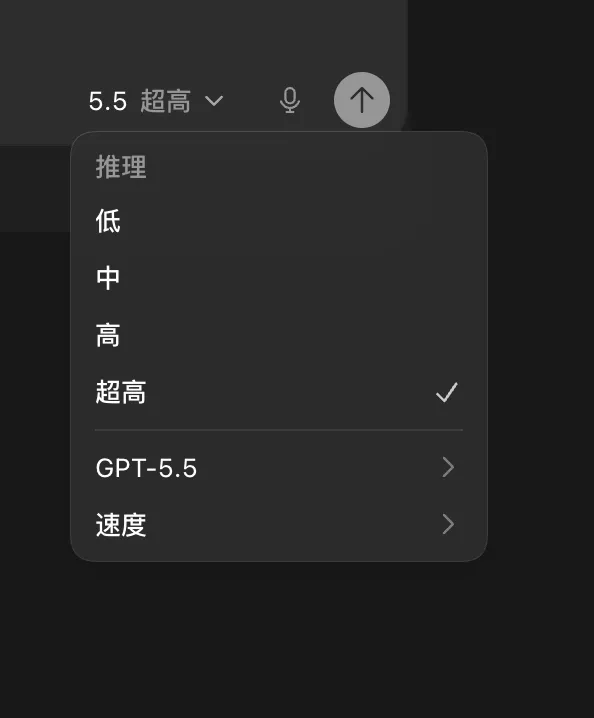
1、速度选择
Codex似乎默认设置的就是快速模式。
快速模式可以让模型的返回速度更快,从而更加节省时间。但问题是,快速模式消耗的token将会是标准模式的1.5倍。
但,快速模式,也只是速度更快了一些。同样的token,不会让你有更多的产出。
所以,如果不是很赶时间的话,那就用标准模式吧。
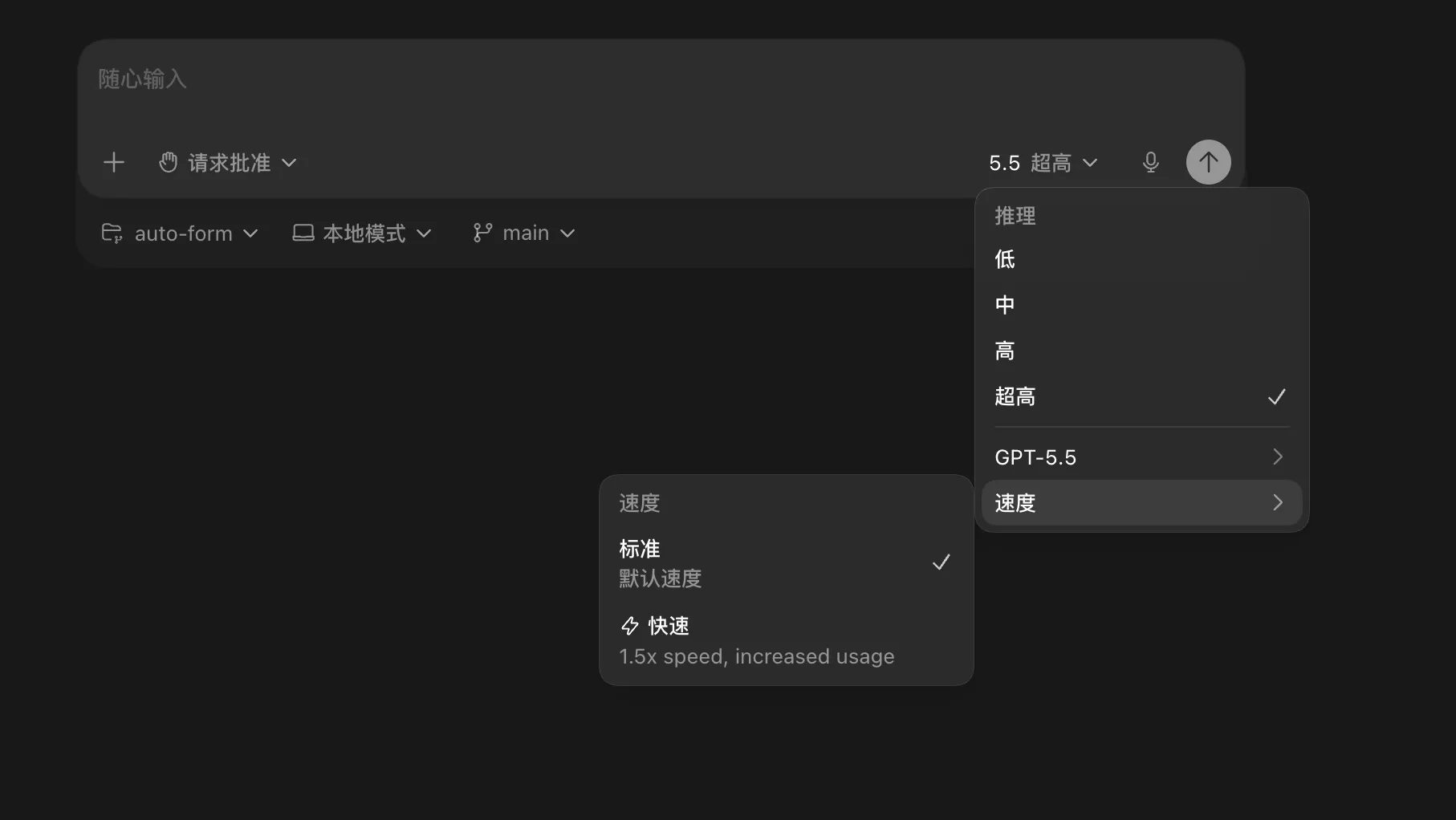
2、推理选择
一直以来的习惯性的偏好,模型都用最好的。所以,推理的选择也一直选超高。这也是token消耗特别快的原因之一。
但实际上,通过我这段时间的实际使用,对推理的选择,最佳实践是这样的:
写文章之类的,推理用“中”就可以了,用“高”或“超高”,结果并不会有明显的更好。
大多数时候的写代码,推理用“高”就可以了,用“超高”,并没有那个必要。
只有在要做一个有比较复杂逻辑的东西的时候,再用“超高”。
另外,如果是分析项目,给出参考建议的时候,可以用“超高”,因为这样最大限度地得到最佳答案,并且,这种情况一般并不会消耗太多token。
还有一个“低”,在很多自动化的场景中,因为不需要AI有太多推理,只需要按照既定的一些东西去执行,所以,这个时候用“低”即可。
不同场景和任务,设置合适的推理程度,不仅不会降低最后的效果,而且还能节省不少token。
3、一个对话,不要有太多轮
很多人,用AI,往往一个对话,会有非常多轮。我有时候也会这样。但这样,不仅仅非常消耗token,而且轮次过多的时候,你会发现AI给的结果,问题也会越来越多。
所以,一个对话,不要有太多轮,一方面节省token,一方面提高AI产出的质量。
相关文章

如何创建AI Agent友好的项目
从项目结构、命名语义、目录层级和 AGENTS.md 规范四个方面,介绍如何让项目更适合 AI Agent 高效理解与修改。
Codex + Astro:做内容和发布内容的最佳组合
用Codex生成文字、图片、视频、3D内容,用Astro一键发布到Web。推荐这个AI时代最高效的内容创作和发布组合。
EaseChart:如何把AI生成的流程图嵌入Notion
在EaseChart中创建流程图后,通过生成嵌入链接,即可将流程图嵌入到Notion、飞书等常见在线文档工具中。